本章在之前对注意力机制的基础上,介绍几种改进的注意力机制,包括多查询注意力(MQA)、分组查询注意力(GQA)以及FlashAttention等技术,这些技术在提升模型性能和推理效率方面发挥了重要作用。
-

-

Pre-trained Language Models介绍
本文详细介绍了预训练语言模型(Pre-trained Language Models, PLM)的核心架构与代表模型,重点分析了 Encoder-only、Encoder-Decoder 和 Decoder-only 三种主流设计思路及其在自然语言处理任务中的应用优势。
-

Transformer架构详解
本章我们将介绍如何搭建一个完整的 Transformer 模型。
-

Attention is all you need
本篇主要讲解了注意力机制(Attention Mechanism)的基本原理和计算过程,包括各种优化技巧,如缩放点积注意力(Scaled Dot-Product Attention)、自注意力(Self-Attention)、掩码自注意力(Masked Self-Attention)和多头注意力(Multi-Head Attention)。
-
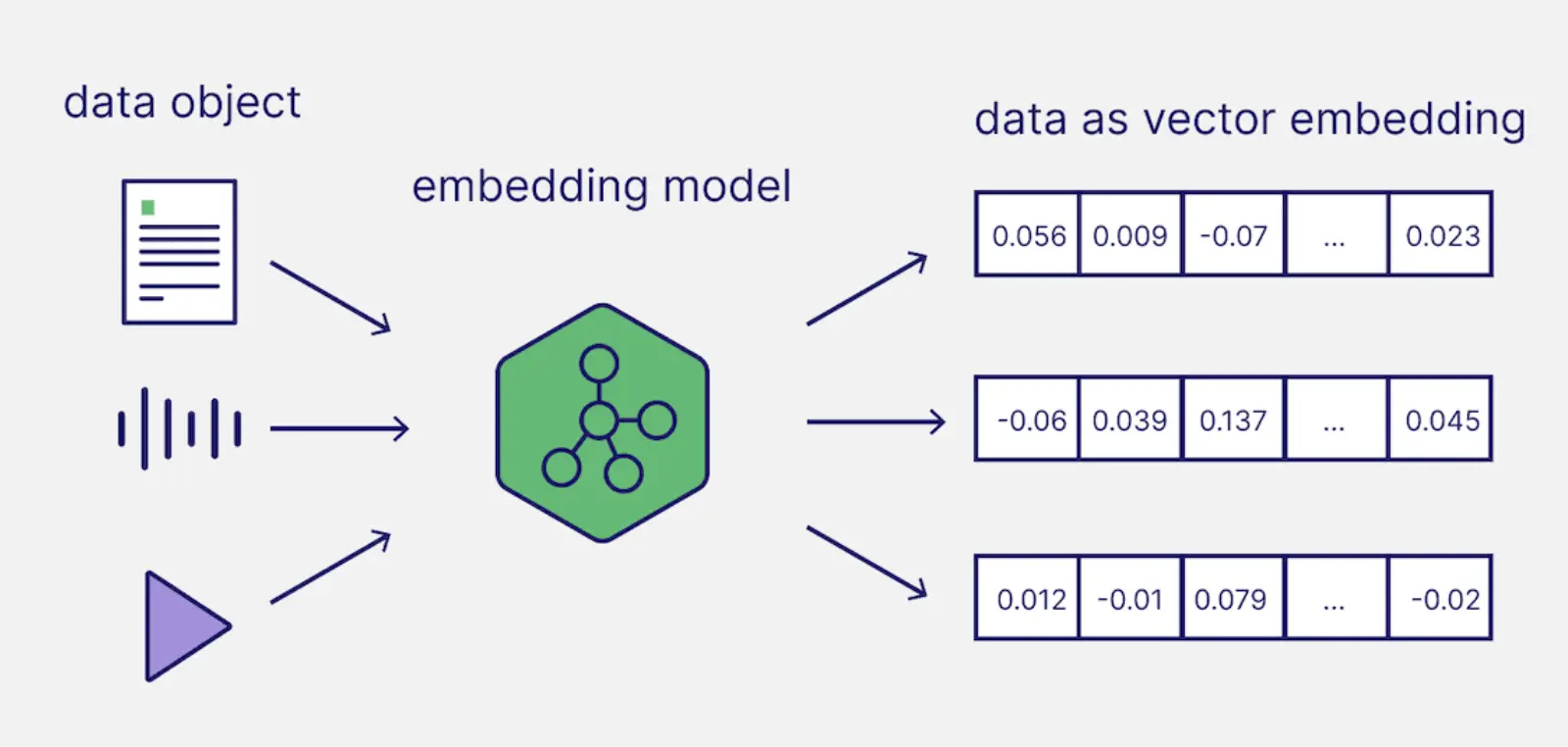
常见的 LLM 文本嵌入(Embedding)方法解析
本篇文章介绍大语言模型(LLM)中常用的文本嵌入(Embedding)方法,包括传统的 One-Hot 编码、词袋模型(BoW)、TF-IDF 以及现代的词向量(Word Embedding)技术。每种方法的原理、优缺点及其在实际中的应用场景都会进行详细讲解,并附有代码示例以帮助理解。
-
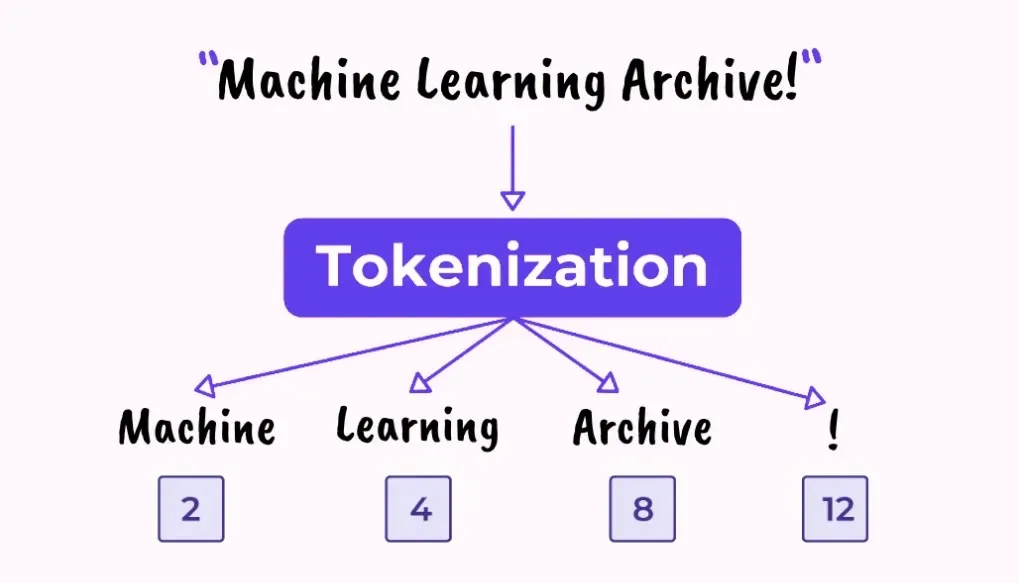
常见的 LLM 分词器(Tokenizer)
本篇文章介绍大语言模型(LLM)中常用的几种分词(Tokenizer)方法,包括传统分词、BPE、WordPiece、SentencePiece 以及 Unigram Language Model。我们将通过原理解析、应用场景和代码示例,帮助读者理解这些分词技术在 LLM 中的作用与实现。
-
Retrieval-Augmented Generation (RAG) 系统实现
本篇文章实现了一个 从零开始构建的多模态检索增强生成(RAG)系统,融合了 BM25 语义检索 + Dense 向量检索 + Cross-Encoder 重排序 + LLM 回答生成 的完整流程。
目标是模拟真实生产中的 RAG 管线,实现一个可复用的、轻量级的本地 RAG 框架。
-
Naïve RAG
最基础的 RAG 实现:TF-IDF 与 BM25 检索器解析
-
Docker项目迁移Debug
容器化部署DOJ项目时遇到的各种坑与解决方案实录,涵盖从打包、内存管理、Nginx配置到Docker-in-Docker的方方面面,帮助开发者顺利完成微服务架构的容器化转型。
-
常用排序算法的选择之道
本文深入探讨常用排序算法的原理、实现及其优缺点,面试专用。