Q1 100214. 边界上的蚂蚁 [Easy] 题解
Q2 100189. 找出网格的区域平均强度 [Medium] 题解
Q3 100203. 将单词恢复初始状态所需的最短时间 [Hard] 题解
100214. 边界上的蚂蚁
边界上有一只蚂蚁,它有时向 左 走,有时向 右 走。
给你一个 非零 整数数组 nums
。蚂蚁会按顺序读取 nums
中的元素,从第一个元素开始直到结束。每一步,蚂蚁会根据当前元素的值移动:
- 如果
nums[i] < 0,向 左 移动-nums[i]单位。 - 如果
nums[i] > 0,向 右 移动nums[i]单位。
返回蚂蚁 返回 到边界上的次数。
注意:
- 边界两侧有无限的空间。
- 只有在蚂蚁移动了
|nums[i]|单位后才检查它是否位于边界上。换句话说,如果蚂蚁只是在移动过程中穿过了边界,则不会计算在内。
示例 1:
1 | 输入:nums = [2,3,-5] |
示例 2:
1 | 输入:nums = [3,2,-3,-4] |
提示:
1 <= nums.length <= 100-10 <= nums[i] <= 10nums[i] != 0
思路
模拟一下即可。
代码
1 | function returnToBoundaryCount(nums: number[]): number { |
复杂度分析
- 时间:O(n)。
- 空间:O(1)。
100189. 找出网格的区域平均强度
给你一个下标从 0 开始、大小为 m x n
的网格 image ,表示一个灰度图像,其中
image[i][j] 表示在范围 [0..255]
内的某个像素强度。另给你一个 非负 整数
threshold 。
如果 image[a][b] 和 image[c][d] 满足
|a - c| + |b - d| == 1 ,则称这两个像素是
相邻像素 。
区域 是一个 3 x 3
的子网格,且满足区域中任意两个 相邻
像素之间,像素强度的 绝对差 小于或等于
threshold 。
区域 内的所有像素都认为属于该区域,而一个像素 可以 属于 多个 区域。
你需要计算一个下标从 0 开始、大小为
m x n 的网格 result ,其中
result[i][j] 是 image[i][j] 所属区域的
平均 强度,向下取整
到最接近的整数。如果 image[i][j]
属于多个区域,result[i][j] 是这些区域的
“取整后的平均强度” 的 平均值,也
向下取整 到最接近的整数。如果 image[i][j]
不属于任何区域,则 result[i][j] 等于
image[i][j] 。
返回网格 result 。
示例 1:
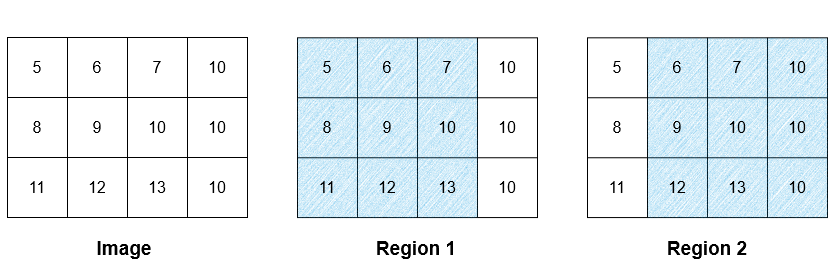
1 | 输入:image = [[5,6,7,10],[8,9,10,10],[11,12,13,10]], threshold = 3 |
示例 2:
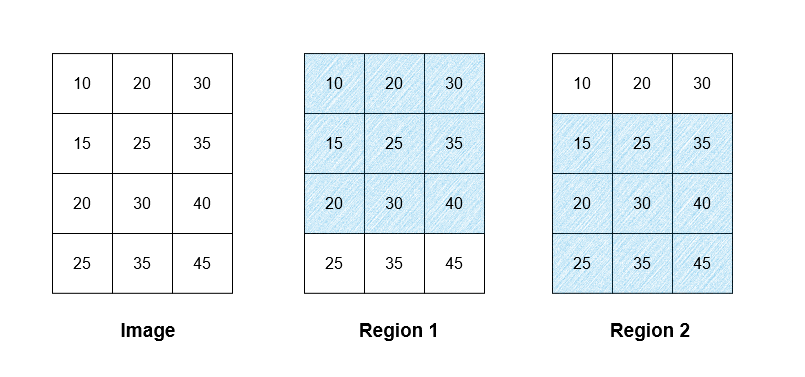
1 | 输入:image = [[10,20,30],[15,25,35],[20,30,40],[25,35,45]], threshold = 12 |
示例 3:
1 | 输入:image = [[5,6,7],[8,9,10],[11,12,13]], threshold = 1 |
提示:
3 <= n, m <= 5000 <= image[i][j] <= 2550 <= threshold <= 255
思路
阅读理解题。
- 遍历每一个3X3方格。
- 维护一个dp数组:dp(i)(j)[0]表示该像素所属区域强度和,dp(i)(j)[1]表示该像素总共属于多少个区域。
- 判断该方格是否为一个区域:即判断相邻格子像素差是否小于threshold
- 如果是区域:则再次遍历区域中每一个像素,维护dp数组值。
- 最后dp(i)(j)[0]/dp(i)(j)[1]则是每个像素所属区域强度和的均值;
- 如果dp(i)(j)[0]等于0,说明像素不属于任何一个区域,答案是它自己像素值。
代码
1 | class Solution { |
复杂度分析
- 时间:O(n*m*9)。
- 空间:O(n*m)。
100203. 将单词恢复初始状态所需的最短时间
给你一个下标从 0 开始的字符串 word
和一个整数 k 。
在每一秒,你必须执行以下操作:
- 移除
word的前k个字符。 - 在
word的末尾添加k个任意字符。
注意 添加的字符不必和移除的字符相同。但是,必须在每一秒钟都执行 两种 操作。
返回将 word 恢复到其 初始 状态所需的
最短 时间(该时间必须大于零)。
示例 1:
1 | 输入:word = "abacaba", k = 3 |
示例 2:
1 | 输入:word = "abacaba", k = 4 |
示例 3:
1 | 输入:word = "abcbabcd", k = 2 |
提示:
1 <= word.length <= 10^51 <= k <= word.lengthword仅由小写英文字母组成。
思路
由于可以往s的末尾添加任意字符,这意味着只要s[k:]是s的前缀,就能让s恢复成其初始值,其中s[k:]表示从s[k]开始的后缀。
即需要找到最小的t,使得s[tk:]是s的前缀。
1
2
3s = abacaba,k = 4 时
第一秒后,s[4:]=aba,是s的前缀。
相当于最前面删除abac,最后面加上caba。1
2
3
4s = abacaba,k = 3 时
第一秒后,s[3:]=caba,不是s的前缀。
第二秒后,s[6:]=a,是s的前缀。
相当于最前面删除aba和cab,最后面加上bac和aba。判断前后缀一般有两种方法:
- KMP
- 字符串哈希
代码
KMP
next[i]表示最长相同前后缀的长度。
例如:next(s = abacaba) = [0,0,1,0,1,2,3],k = 3。
一开始相同前后缀长度 len = next[n-1] = 3。(此时前后缀为aba)。
但需要删除abac四个字符,不是k的整数倍。再次寻找次短相同前后缀长度。
len = next[len-1] = next[2] = 1。(此时前后缀为a)。
需要删除abacab六个字符,是k的两倍,符合题意。
1 | class Solution { |
- 时间:O(n)。
- 空间:O(n)。