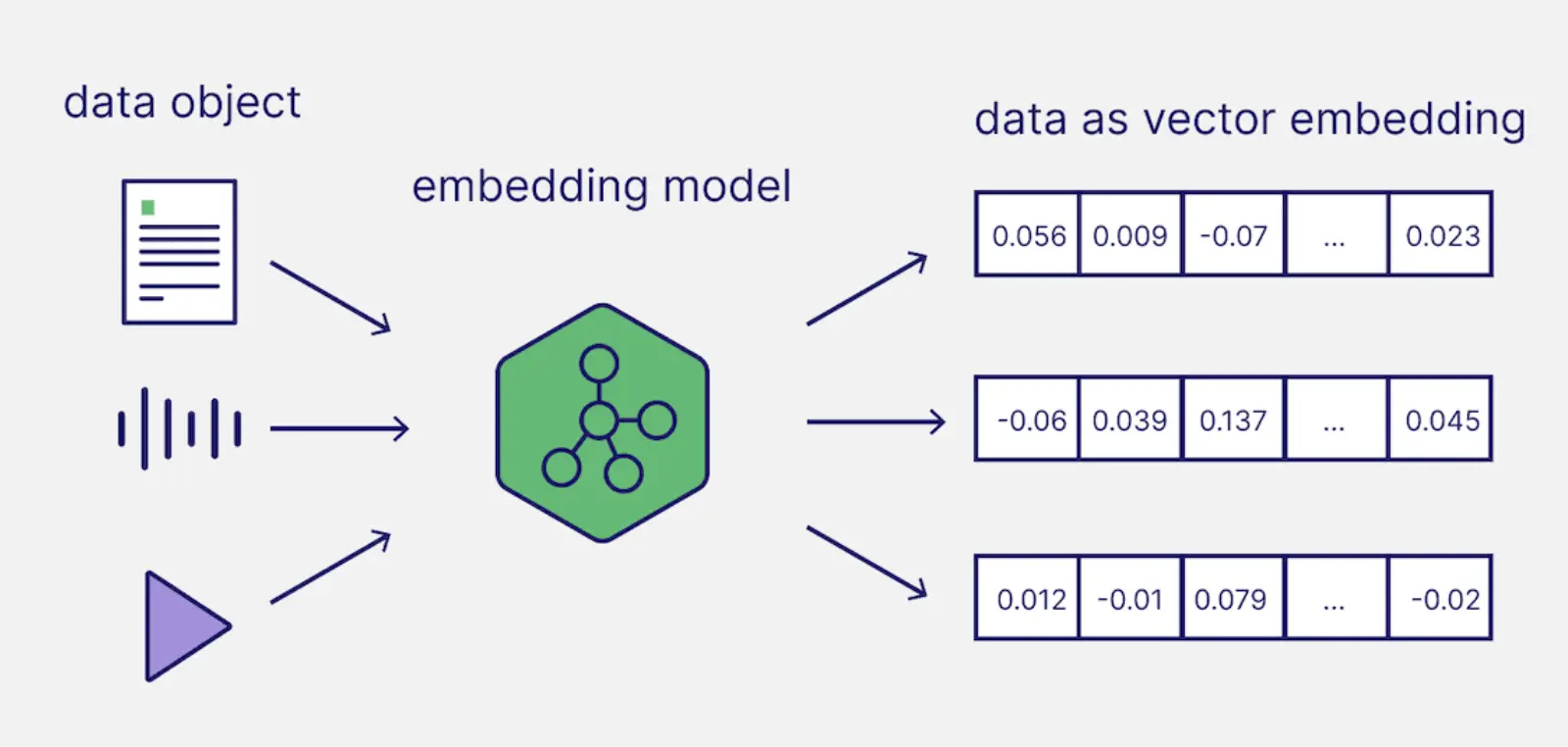
本篇文章介绍大语言模型(LLM)中常用的文本嵌入(Embedding)方法,包括传统的
One-Hot 编码、词袋模型(BoW)、TF-IDF 以及现代的词向量(Word
Embedding)技术。每种方法的原理、优缺点及其在实际中的应用场景都会进行详细讲解,并附有代码示例以帮助理解。
💡
引言:大语言模型(LLM)的第二块基石——Embedding
在上一篇中,我们探讨了 Tokenizer
如何将文本转化为机器可读的 Token ID
序列 。然而,这些简单的 ID 数字(如
[464, 9016, 2793, ...])本身不包含任何语义信息。模型知道 ID
9016 对应 “lowest”,但不知道它与 ID 2793 对应的 “lower”
在意义上是相似的,而与 ID 4000 对应的 “banana” 是不相关的。
要让机器真正理解语言的意义、上下文和关系 ,我们需要一个机制将离散的、毫无关联的
Token ID
转化为连续的、具有丰富语义信息的向量(Vector) 表示。这个机制就是
Embedding(词嵌入或令牌嵌入) 。
为什么 Embedding 是 LLM
的核心组件?
语义表示(Semantic Representation) :Embedding
是一张高维空间中的“地图”。它通过学习,将具有相似意义的 Token
放置在这个空间中彼此接近 的位置。例如,在向量空间中,Vector(“King”) − Vector(“Man”) + Vector(“Woman”)
约等于 Vector(“Queen”) ,这体现了语言内在的代数关系。降维与特征提取(Dimensionality Reduction &
Features) :Embedding 将庞大且稀疏的词汇表(数万个
Token)映射到相对低维且密集的向量空间(如 768 维或 4096
维),极大地提高了模型的计算效率和学习能力。模型兼容性(Neural Network Compatibility) :无论是
Transformer 架构、RNN 还是
CNN,它们都需要连续的、可微分的数值输入才能进行梯度下降和训练。Embedding
层正是提供了这种可学习的数值化表示 ,是整个深度学习模型接收输入的必经之路。
1. One-Hot 编码(独热表示)
💡 主要思想与原理
One-Hot
编码是一种稀疏、高维、离散 的向量表示方法,也是最早、最直观的文本表示方式。
原理: 首先,对训练语料中的所有不重复的词(或
Token)建立一个词汇表 V |V | 即为向量的维度。表示: 词 w v w |V |
的向量,其中只有对应于 w 1 ,其他位置均为
0 。
🧐 缺点分析
维度灾难:
当词汇表很大时(如几十万),向量维度极高,且绝大多数元素是
0(稀疏),计算效率低下。语义鸿沟: 任意两个词的 One-Hot
向量的点积(或余弦相似度)总是
0,表示它们之间完全独立 。这无法体现词汇间的任何语义关系(例如:“猫”和“虎”很相似,但它们的
One-Hot 向量距离与“猫”和“宇宙飞船”的距离是相同的)。
💻 示例(Python 实现)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import numpy as npvocab = ['我' , '爱' , '学习' , '自然语言处理' , '技术' ] vocab_size = len (vocab) word_to_idx = {word: i for i, word in enumerate (vocab)} def one_hot_encode (word ): """为给定词生成 One-Hot 向量""" if word not in word_to_idx: raise ValueError(f"'{word} ' 不在词汇表中。" ) vector = np.zeros(vocab_size) index = word_to_idx[word] vector[index] = 1 return vector word_study = '学习' vector_study = one_hot_encode(word_study) print (f"词汇表大小: {vocab_size} " )print (f"'{word_study} ' 的 One-Hot 向量: {vector_study} " )word_tech = '技术' vector_tech = one_hot_encode(word_tech) print (f"'{word_tech} ' 的 One-Hot 向量: {vector_tech} " )similarity = np.dot(vector_study, vector_tech) print (f"'{word_study} ' 和 '{word_tech} ' 的相似度: {similarity} " )
1 2 3 4 词汇表大小: 5 '学习' 的 One-Hot 向量: [0. 0. 1. 0. 0.] '技术' 的 One-Hot 向量: [0. 0. 0. 0. 1.] '学习' 和 '技术' 的相似度: 0.0
也可以用现成的库
1 2 3 4 5 6 7 8 9 10 from sklearn.preprocessing import OneHotEncoderimport numpy as npcorpus = [["我" ], ["爱" ], ["自然语言" ], ["处理" ]] enc = OneHotEncoder(sparse_output=False ) onehot = enc.fit_transform(corpus) print ("词表:" , enc.categories_)print ("One-hot 表示:\n" , onehot)
1 2 3 4 5 6 词表: [array (['处理' , '我' , '爱' , '自然语言' ], dtype=object)] One-hot 表示: [[0. 1. 0. 0. ] [0. 0. 1. 0. ] [0. 0. 0. 1. ] [1. 0. 0. 0. ]]
2. 词袋编码及优化(BoW, N-gram,
TF-IDF)
🧠 主要思想与原理
这类方法将一个文档表示为一个向量,向量的每个维度对应词汇表中的一个词。它们主要关注词汇的频率或重要性 ,忽略词序 。
2.1 词袋模型 (Bag-of-Words, BoW)
思想:
将文档视为“一袋子”词语的集合,只统计词语的出现次数 (Term
Frequency, TF),完全不考虑词语出现的顺序和语法结构。原理: 文档向量 d i i C o u n t (w i d )
词袋模型(BoW) 将文本表示为
词频统计向量 :
忽略词序,仅统计每个词出现次数
每个文档表示为 “词频分布”
例如,语料为:
1 2 Doc1: 我 爱 自然 语言 Doc2: 我 爱 处理
则词表为 [我, 爱, 自然语言, 处理] 表示为:
文档
我
爱
自然
语言
处理
Doc1
1
1
1
1
0
Doc2
1
1
0
0
1
这就是最原始的 BoW。
2.2 N-gram
思想: 对 BoW
模型的词序盲点 进行优化,将连续的 N 原理: 当 N = 2我、爱、NLP、我 爱、爱 NLP。它部分地保留了局部词序信息。
例如第一个文档为:“我 爱 自然 语言 处理”,那其对应的词表如下
n
n-gram 示例
1
我, 爱, 自然, 语言, 处理
2
我爱, 爱自然, 自然语言, 语言处理
3
我爱自然, 爱自然语言, 自然语言处理
假设第二个文档是:“我 爱 机器 学习”
它的 bigram 特征为:我爱, 爱机器, 机器学习
合并整个语料的 2-gram 词表:V = 我爱, 爱自然, 自然语言, 语言处理, 爱机器, 机器学习
对应的 BoW 矩阵为:
doc
我爱
爱自然
自然语言
语言处理
爱机器
机器学习
doc1 (“我爱自然语言处理”)
1
1
1
1
0
0
doc2 (“我爱机器学习”)
1
0
0
0
1
1
2.3 TF-IDF
BoW
只看词频,不考虑词的重要性。一些高频的功能词(如“我”“是”“的”)在几乎所有文档中都会出现,但它们并不能区分语义 。BoW
因此会让无信息的常见词占据较大权重,导致文本相似度计算或分类性能下降。
TF-IDF中每个文档被表示为一个向量,其每一维对应语料库中的一个词,值为该词在该文档中的
TF-IDF 权重。
思想: 提升 BoW
模型中对词语重要性的判断。一个词的重要性与它在文档中出现的频率成正比 (T F 反比 (I D F 原理:
词频 (TF): 词 在 文 档 中 出 现 的 次 数 文 档 总 词 数 逆文档频率 (IDF): 文 档 总 数 包 含 词 的 文 档 数 TF-IDF: T F I D F (w ) = T F (w ) × I D F (w )高 T F I D F
优点:
简单有效,不需要语义模型,也能很好区分文档特征
抑制无用词,自动降低“我”“是”“的”等停用词的权重
缺点(也是BoW和n-gram的缺点) :
无法捕捉语序:“语言 自然”与“自然 语言”同样处理
忽略词义相似:“学习”与“研究”视为完全不同
静态权重:不能根据上下文动态调整,即一个词在不同上下文里表达的意思可能是完全不同的
稀疏高维:大语料下向量维度极大,计算耗时高
💻 示例(Scikit-learn
实现 BoW, N-gram, TF-IDF)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizerimport jiebadocuments = [ "The quick brown fox jumps over the lazy dog." , "A quick brown fox is better than a lazy dog." , "The lowest lower technologies are amazing and counterproductive." , "我爱自然语言处理,并且明天早上吃什么? 我爱吃枇杷!" ] print ("--- 原始文档 ---" )for doc in documents: print (f"- {doc} " ) count_vectorizer = CountVectorizer(token_pattern=r'(?u)\b\w\w+\b' ) X_bow = count_vectorizer.fit_transform(documents) print ("\n--- 1. BoW 词频矩阵 (CountVectorizer) ---" )print ("词汇表:" , count_vectorizer.get_feature_names_out())print ("Doc 向量表示:" )print (X_bow.toarray())ngram_vectorizer = CountVectorizer(ngram_range=(2 , 2 )) X_ngram = ngram_vectorizer.fit_transform(documents) print ("\n--- 2. N-gram (Bi-gram) 词汇表 ---" )print ("词汇表:" , ngram_vectorizer.get_feature_names_out())print ("Doc 向量表示:" )print (X_ngram.toarray())tfidf_vectorizer = TfidfVectorizer() X_tfidf = tfidf_vectorizer.fit_transform(documents) print ("\n--- 3. TF-IDF 矩阵 ---" )print ("词汇表:" , tfidf_vectorizer.get_feature_names_out())print ("Doc 向量表示:" )print (X_tfidf.toarray())feature_names = tfidf_vectorizer.get_feature_names_out() for idx, doc_vec in enumerate (X_tfidf.toarray()): print (f"\n--- 文档 {idx} 的 TF-IDF 特征 ---" ) for value, word in sorted (zip (doc_vec, feature_names), reverse=True ): if value > 0 : print (f"({value:.4 f} , '{word} ')" )
BoW表示结果
1 2 3 4 5 6 7 8 9 --- 1. BoW 词频矩阵 (CountVectorizer) --- 词汇表: ['amazing' 'and' 'are' 'better' 'brown' 'counterproductive' 'dog' 'fox' 'is' 'jumps' 'lazy' 'lower' 'lowest' 'over' 'quick' 'technologies' 'than' 'the' '并且明天早上吃什么' '我爱吃枇杷' '我爱自然语言处理'] Doc 向量表示: [[0 0 0 0 1 0 1 1 0 1 1 0 0 1 1 0 0 2 0 0 0] [0 0 0 1 1 0 1 1 1 0 1 0 0 0 1 0 1 0 0 0 0] [1 1 1 0 0 1 0 0 0 0 0 1 1 0 0 1 0 1 0 0 0] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1]]
就是统计每个Doc中各个出现在词表里的单词的频率。
例如第一句话 “The quick brown fox jumps over the lazy
dog.”中,单词”The”出现2次,于是计算出的表示向量中倒数第四个值就是2。
token_pattern=r’(?u)+
表示分词的方法,根据正则表达式 来切 token:(?u)表示使用 Unicode
字符规则,,+表示匹配至少2个字母/数字/下划线。(即不包括任何标点符号和空格 )
你也可以替换成其他比较成熟的分词方法,利用tokenizer 参数
1 count_vectorizer = CountVectorizer(tokenizer=list )
1 2 3 4 5 6 7 8 9 10 11 12 词汇表: [' ' '.' 'a' 'b' 'c' 'd' 'e' 'f' 'g' 'h' 'i' 'j' 'k' 'l' 'm' 'n' 'o' 'p' 'q' 'r' 's' 't' 'u' 'v' 'w' 'x' 'y' 'z' '上' '且' '么' '什' '吃' '处' '天' '并' '我' '早' '明' '杷' '枇' '然' '爱' '理' '自' '言' '语' '!' ',' '?'] Doc 向量表示: [[8 1 1 1 1 1 3 1 1 2 1 1 1 1 1 1 4 1 1 2 1 2 2 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [9 1 4 2 1 1 2 1 1 1 2 0 1 1 0 2 3 0 1 2 1 3 1 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [7 1 4 0 3 2 8 0 2 2 3 0 0 3 1 4 6 1 0 4 2 5 2 1 2 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 2 1 1 1 2 1 1 1 1 1 2 1 1 1 1 1 1 1]]
tokenizer=list意思是按照所有字符切分,所以词表就是所有Doc中出现过的字符
n-gram表示结果
1 2 3 4 5 6 7 8 9 10 11 --- 2. N-gram (Bi-gram) 词汇表 --- 词汇表: ['amazing and' 'and counterproductive' 'are amazing' 'better than' 'brown fox' 'fox is' 'fox jumps' 'is better' 'jumps over' 'lazy dog' 'lower technologies' 'lowest lower' 'over the' 'quick brown' 'technologies are' 'than lazy' 'the lazy' 'the lowest' 'the quick' '并且明天早上吃什么 我爱吃枇杷' '我爱自然语言处理 并且明天早上吃什么' ] Doc 向量表示: [[0 0 0 0 1 0 1 0 1 1 0 0 1 1 0 0 1 0 1 0 0 ] [0 0 0 1 1 1 0 1 0 1 0 0 0 1 0 1 0 0 0 0 0 ] [1 1 1 0 0 0 0 0 0 0 1 1 0 0 1 0 0 1 0 0 0 ] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 ]]
因为我们使用的是ngram_range=(2,
2),即将相邻的两个词作为一个Token进行处理,所以词表中都是两个单词组合(中文默认是两个子句组合,因为在大部分分词器中,对中文没有细粒度的分词考虑)
TF-IDF表示结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 词汇表: ['amazing' 'and' 'are' 'better' 'brown' 'counterproductive' 'dog' 'fox' 'is' 'jumps' 'lazy' 'lower' 'lowest' 'over' 'quick' 'technologies' 'than' 'the' '并且明天早上吃什么' '我爱吃枇杷' '我爱自然语言处理'] Doc 向量表示: [[0. 0. 0. 0. 0.28609357 0. 0.28609357 0.28609357 0. 0.36287342 0.28609357 0. 0. 0.36287342 0.28609357 0. 0. 0.57218714 0. 0. 0. ] [0. 0. 0. 0.40462414 0.31901032 0. 0.31901032 0.31901032 0.40462414 0. 0.31901032 0. 0. 0. 0.31901032 0. 0.40462414 0. 0. 0. 0. ] [0.36222393 0.36222393 0.36222393 0. 0. 0.36222393 0. 0. 0. 0. 0. 0.36222393 0.36222393 0. 0. 0.36222393 0. 0.2855815 0. 0. 0. ] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.57735027 0.57735027 0.57735027]] --- 文档 0 的 TF-IDF 特征 --- (0.5722, 'the') (0.3629, 'over') (0.3629, 'jumps') (0.2861, 'quick') (0.2861, 'lazy') (0.2861, 'fox') (0.2861, 'dog') (0.2861, 'brown') --- 文档 1 的 TF-IDF 特征 --- (0.4046, 'than') (0.4046, 'is') (0.4046, 'better') (0.3190, 'quick') (0.3190, 'lazy') (0.3190, 'fox') (0.3190, 'dog') (0.3190, 'brown') --- 文档 2 的 TF-IDF 特征 --- (0.3622, 'technologies') (0.3622, 'lowest') (0.3622, 'lower') (0.3622, 'counterproductive') (0.3622, 'are') (0.3622, 'and') (0.3622, 'amazing') (0.2856, 'the') --- 文档 3 的 TF-IDF 特征 --- (0.5774, '我爱自然语言处理') (0.5774, '我爱吃枇杷') (0.5774, '并且明天早上吃什么')
TF-IDF是利用TF-IDF指标进行表示的,所以向量里的数值不再是整数了。
可以仔细看一下文档 2 的 TF-IDF
特征,除了单词”The”,其他词的TF-IDF数值都一样。这是因为所有词在Doc2中都出现了一次,即TF=1;但对于其他单词,在语料中其他Doc中都没有出现过,只有”The”除外,所以其对应的IDF就小,意思是”The”这个词是一个常用的词,语义在这个文档里不是很重要。
我们可以使用其他对中文比较友好的分词器看看效果:tfidf_vectorizer = TfidfVectorizer(*tokenizer*=jieba.lcut)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 --- 3. TF-IDF 矩阵 --- 词汇表: [' ' '.' 'a' 'amazing' 'and' 'are' 'better' 'brown' 'counterproductive' 'dog' 'fox' 'is' 'jumps' 'lazy' 'lower' 'lowest' 'over' 'quick' 'technologies' 'than' 'the' '什么' '吃' '处理' '并且' '我' '早上' '明天' '枇杷' '爱' '自然语言' '!' ',' '?'] --- 文档 0 的 TF-IDF 特征 --- (0.8279, ' ') (0.3127, 'the') (0.1983, 'over') (0.1983, 'jumps') (0.1563, 'quick') (0.1563, 'lazy') (0.1563, 'fox') (0.1563, 'dog') (0.1563, 'brown') (0.1266, '.') --- 文档 1 的 TF-IDF 特征 --- (0.8229, ' ') (0.3504, 'a') (0.1752, 'than') (0.1752, 'is') (0.1752, 'better') (0.1381, 'quick') (0.1381, 'lazy') (0.1381, 'fox') (0.1381, 'dog') (0.1381, 'brown') (0.1118, '.') --- 文档 2 的 TF-IDF 特征 --- (0.7901, ' ') (0.2163, 'technologies') (0.2163, 'lowest') (0.2163, 'lower') (0.2163, 'counterproductive') (0.2163, 'are') (0.2163, 'and') (0.2163, 'amazing') (0.1705, 'the') (0.1381, '.') --- 文档 3 的 TF-IDF 特征 --- (0.4238, '爱') (0.4238, '我') (0.4238, '吃') (0.2119, '?') (0.2119, ',') (0.2119, '!') (0.2119, '自然语言') (0.2119, '枇杷') (0.2119, '明天') (0.2119, '早上') (0.2119, '并且') (0.2119, '处理') (0.2119, '什么') (0.1106, ' ')
jieba分词器默认也会考虑所有标点符号和空格,所以词表里也会有这些内容。
并且对于中文分词也更加地合理。
3. 词向量(Word Embedding)
🌈 主要思想与原理
BoW/TF-IDF 是稀疏、高维、无语义 的;词向量(Word
Embedding)是低维、稠密、连续 的向量表示方法
思想: 遵循“分布假说 (Distributional
Hypothesis) ”,即上下文相似的词,它们的语义也相似 。通过大规模语料的训练,让模型自动学习词语的语义表示。原理:
将每个词映射到一个固定长度的实数向量(如 100 维、300 维)。
向量的每个维度没有明确含义,但整个向量空间能够捕捉词语之间的语义关系。例如,在向量空间中,vec(国王) − vec(男人) + vec(女人) ≈ vec(王后) 。
常见方法:Word2Vec
Word2Vec 是最经典的词向量生成模型,包含两种结构:
CBOW (Continuous Bag-of-Words): 用上下文词语预测当前词语。
Skip-gram: 用当前词语预测上下文词语。
这里并不讲 Word2Vec 模型的原理和实现,想知道的读者可以自行搜索
Word2Vec 并不是用来直接预测下一个词的语言模型(那是 GPT
的方向)。
它的目标是:通过上下文预测任务,学习一个能够捕捉语义的词向量空间。
换句话说:
我们并不关心预测结果本身对不对;
我们关心的是:为了预测正确,模型必须把语义相似的词放得更近;
而模型内部权重矩阵(embedding)就是我们想要的词向量表示(word
embeddings) 。
假设词表大小为 V x ∈ ℝV W ∈ ℝV × d v w W T x
CBOW 训练方法
句子:「我 爱 自然 语言 处理」
目标中心词是「自然」,窗口大小=2,则上下文为「我, 爱, 语言, 处理」。
训练目标:如果上下文是“我爱语言处理”,那“自然”的词向量应该更靠近这一上下文的平均表示。
Skip-gram 训练方法
同样一句话,「自然」是中心词,它的上下文是「我, 爱, 语言, 处理」。
训练目标:如果当前词是“自然”,模型希望它的词向量能够预测出上下文中的每一个词,也就是“我”“爱”“语言”“处理”。
换句话说,模型通过让“自然”的向量尽可能靠近它经常出现的上下文词向量,从而捕捉“自然”的语义信息。训练完成后,“自然”的词向量就自然形成了,并且语义上会靠近类似的词,例如“语言”、“文本”等。
为什么“预测任务”能学出语义?
Word2Vec 的核心假设是:
上下文相似的词,其语义也相似。
在训练过程中:
狗和猫经常出现在相似的上下文(例如’喂..’,‘宠物..’)
模型会让它们的词向量都靠近这些上下文向量;
最终它们的词向量也就靠近了。
📦 应用场景
预训练特征: 作为所有下游 NLP
任务(分类、命名实体识别、翻译等)的输入特征。语义相似度计算: 直接计算词向量的余弦相似度。词语类比: 进行向量代数运算来发现语义关系。
💻 示例(Gensim Word2Vec
Skip-gram 实现)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 from gensim.models import Word2Vecimport jiebacorpus_text = """ 自然语言处理是人工智能的重要分支。机器学习和深度学习是人工智能的核心技术。 词向量是自然语言处理的基础。词向量可以表示词语的语义信息。 国王是男性统治者,王后是女性统治者。男人和女人有不同的性别特征。 狗是人类的好朋友。猫也是常见的宠物。人们喜欢养狗和猫作为宠物。 机器学习包括监督学习和无监督学习。深度学习是机器学习的一个重要方向。 自然语言处理应用广泛,包括机器翻译、文本分类、情感分析等任务。 Python是流行的编程语言。Java也是常用的编程语言。编程语言用于软件开发。 北京是中国的首都。上海是中国的经济中心。中国有很多大城市。 苹果是健康的水果。香蕉也是营养丰富的水果。水果富含维生素。 足球是流行的运动。篮球也是受欢迎的运动。运动有益于身体健康。 电影是娱乐方式。音乐也是常见的娱乐。人们通过娱乐放松身心。 学习需要努力和坚持。努力工作才能成功。成功需要坚持不懈。 计算机科学是重要学科。数学是科学的基础。物理学研究自然规律。 医生治病救人。教师教书育人。工程师设计和建造。 春天温暖宜人。夏天炎热多雨。秋天凉爽舒适。冬天寒冷干燥。 阅读可以增长知识。写作能够表达思想。思考帮助理解问题。 美食令人愉悦。烹饪是一门艺术。餐厅提供各种美食。 汽车是交通工具。飞机速度更快。火车适合长途旅行。 手机是通讯设备。电脑用于办公学习。互联网连接世界。 音乐能够陶冶情操。绘画展现艺术之美。舞蹈表达身体语言。 """ * 5 sentences = [ ["我" , "爱" , "自然" , "语言处理" , "技术" ], ["词向量" , "是" , "自然" , "语言处理" , "的" , "基石" ], ["机器学习" , "和" , "深度学习" , "是" , "主流" , "方法" ], ["国王" , "男人" , "女人" , "王后" ], ["爱" , "和" , "和平" , "是" , "永恒" , "的主题" ], ] for line in corpus_text.strip().split('\n' ): if line.strip(): words = list (jieba.cut(line.strip())) words = [w for w in words if len (w) > 0 and w not in ',.。,、;:!?!?""' '《》()【】' ] if words: sentences.append(words) model = Word2Vec( sentences, vector_size=32 , window=4 , min_count=0 , sg=1 , epochs=500 ) print ("--- 词向量模型训练结果 ---" )word_love = '爱' print (f"'{word_love} ' 的词向量: {model.wv[word_love]} " )similar_words = model.wv.most_similar('处理' , topn=3 ) print (f"\n与 '处理' 最相似的词 (Top 3): {similar_words} " )analogy = model.wv.most_similar(positive=['王后' , '男人' ], negative=['女人' ], topn=3 ) print (f"\n'王后' + '男人' - '女人' 约等于: {analogy} " )
1 2 3 4 5 6 7 8 9 10 11 --- 词向量模型训练结果 --- '爱' 的词向量: [ 1.0664989 -0.5794411 -0.16871376 -0.13184728 0.48283565 -0.354865 1.3210454 -0.1693582 -0.72543424 -0.2901834 0.21910937 -0.37224293 -0.06491608 -0.8655389 0.39459693 0.8997167 0.24972028 -0.860483 0.76891196 0.03923182 -0.3576591 1.2710804 0.1804323 0.5814926 0.6470771 0.6128785 -1.227191 0.8472333 -1.32114 -0.2857696 -0.04215891 0.9688248 ] 与 '处理' 最相似的词 (Top 3): [('自然语言', 0.8251885175704956), ('核心技术', 0.707213819026947), ('向量', 0.6756125688552856)] '王后' + '男人' - '女人' 约等于: [('国王', 0.8771973848342896), ('统治者', 0.8529900908470154), ('女性', 0.8453759551048279)]
可以发现,Word2Vec 会将每一个 Token(词)
转换为一个固定长度的稠密向量 ,这些向量由正负浮点数构成,能够捕捉词语的语义信息 。例如
处理 的最相似词包括
自然语言、核心技术、向量,它们在语义上都与“处理”相关。这说明训练好的向量空间能够将语义相关的词映射到相近的区域。
此外,实验 '王后' + '男人' - '女人' ≈ '国王'
成功捕捉了性别关系和角色对应关系。这体现了 Word2Vec
的核心优势:不仅表示单个词语,还能隐含语义关系,支持简单的向量运算 。
我们还可以使用训练好的模型来测试,这会比我们自己训练的效果要好很多:
模型二进制文件下载链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from gensim.models import KeyedVectors model = KeyedVectors.load_word2vec_format ("GoogleNews-vectors-negative300.bin" , binary=True) # 获取词向量 print ("--- 词向量模型训练结果 ---" )word_love = '爱' print (f"'{word_love}' 的词向量长度: {model[word_love].shape}" )# 词语相似度计算 similar_words = model.most_similar ('处理' , topn=3 ) print (f"\n与 '处理' 最相似的词 (Top 3): {similar_words}" )similar_words = model.most_similar ("king" , topn=3 ) print ("king 的相似词:" , similar_words)# 词语类比 analogy = model.most_similar (positive=['queen' , 'man' ], negative=['women' ], topn=3 ) print (f"\n'queen' + 'man' - 'women' 约等于: {analogy}" )
1 2 3 4 5 6 7 --- 词向量模型训练结果 --- '爱' 的词向量长度: (300 ,)与 '处理' 最相似的词 (Top 3 ): [('资料' , 0.8521135449409485 ), ('个人' , 0.8465384840965271 ), ('如何' , 0.8432191610336304 )] king 的相似词: [('kings' , 0.7138045430183411 ), ('queen' , 0.6510956883430481 ), ('monarch' , 0.6413194537162781 )] 'queen' + 'man' - 'women' 约等于: [('king' , 0.5553385019302368 ), ('princess' , 0.4909053444862366 ), ('boy' , 0.48070359230041504 )]
首先,该模型中词汇的向量维度是 300
维,这远大于我们在小规模示例中设置的维度。在海量语料上训练的高维向量通常能够捕捉到更丰富、更细致的语义信息。其次,对于语义相似度计算,模型表现出色,可以很精准地找出相似词。
但是,最后这里之所以没有使用’王后’ + ‘男人’ - ‘女人’
的例子,是因为这个训练后的词表中没有’王后’这个词,这也是这类词嵌入方法的固有局限性:它们完全依赖于预设的固定词汇表 ,对于词表中不存在的词(OOV),如新词或跨语言词汇,它们无法生成有效的向量 。
4. 上下文嵌入(Contextual
Embedding)
🚀 主要思想与原理
上下文嵌入是深度学习时代的核心技术,它解决了传统词向量(如
Word2Vec)中一词多义 的问题。
思想:
一个词的向量表示不再是固定不变的 ,而是根据它在当前句子中的上下文 动态生成的。原理:
上下文感知: 使用复杂的神经网络结构(主要是
Transformer 的 Attention
机制 )来处理整个输入序列。
模型在编码一个词时,会同时关注 句子中的其他所有词,并根据这些词的语义信息来调整当前词的向量表示。
例如,在 “我喜欢吃 苹果 ” 和 “我用
苹果 电脑” 中,Transformer 会给两个
“苹果 ”
生成截然不同的向量,分别对应“水果”和“品牌”的语义。
常见模型:BERT & GPT
BERT (Bidirectional Encoder Representations from Transformers):
双向编码器,同时考虑一个词的左侧和右侧上下文。
预训练任务: 掩码语言模型(MLM)和下一句预测(NSP)。
GPT (Generative Pre-trained Transformer):
单向解码器,只依赖左侧上下文,擅长生成任务。
预训练任务:下一个词预测 (Next Token Prediction)。
📦 应用场景
所有 SOTA (State-of-the-Art) NLP 任务:
机器翻译、问答系统、文本摘要、命名实体识别等。零样本/少样本学习 (Zero/Few-shot Learning):
大语言模型的基础。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from transformers import BertModel, BertTokenizerimport torchtokenizer = BertTokenizer.from_pretrained('bert-base-uncased' ) model = BertModel.from_pretrained('bert-base-uncased' ) sentence = "The bank is on the river bank." inputs = tokenizer(sentence, return_tensors="pt" ) print (inputs)with torch.no_grad(): outputs = model(**inputs) print (outputs.keys()) print ("last_hidden_state shape:" , outputs.last_hidden_state.shape) print ("pooler_output shape:" , outputs.pooler_output.shape) last_hidden_state = outputs.last_hidden_state vector_bank_finance = last_hidden_state[0 ][2 ] vector_bank_river = last_hidden_state[0 ][7 ] cos_sim = torch.nn.functional.cosine_similarity( vector_bank_finance.unsqueeze(0 ), vector_bank_river.unsqueeze(0 ) ) print (f"Tokens: {tokenizer.convert_ids_to_tokens(inputs['input_ids' ][0 ])} " )print (f"BERT 向量维度: {vector_bank_finance.shape[0 ]} " )print ("--- 两个 'bank' 的向量表示(前 5 维) ---" )print (f"Bank (金融): {vector_bank_finance[:5 ]} " )print (f"Bank (河岸): {vector_bank_river[:5 ]} " )print (f"\n两个 'bank' 的上下文相似度: {cos_sim.item()} " )
1 2 3 4 5 6 7 8 9 10 11 {'input_ids': tensor([[ 101, 1996, 2924, 2003, 2006, 1996, 2314, 2924, 1012, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])} odict_keys(['last_hidden_state', 'pooler_output']) last_hidden_state shape: torch.Size([1, 10, 768]) pooler_output shape: torch.Size([1, 768]) Tokens: ['[CLS]', 'the', 'bank', 'is', 'on', 'the', 'river', 'bank', '.', '[SEP]'] BERT 向量维度: 768 --- 两个 'bank' 的向量表示(前 5 维) --- Bank (金融): tensor([-0.4117, -0.2152, -0.0635, -0.0978, 0.5961]) Bank (河岸): tensor([-0.1720, -0.2786, -0.0828, -0.4458, 0.2067]) 两个 'bank' 的上下文相似度: 0.7106703519821167
可以看出BERT中每个token都是用一个768维的向量来表征的。
BERT的输出中last_hidden_state是模型对每个 token 输出的隐藏向量,形状
[batch_size, seq_len, hidden_dim]。这里是
[1, 10, 768],表示 1 个句子、10 个 token、每个 token
的向量维度 768。
last_hidden_state[0][i] 就是第 i 个 token
的表示向量。
对于句子中的两个“bank”的表示向量,可以看到每一维的数值不完全相同,说明两者在表示上有差异(模型调整了表示以反映不同上下文)。余弦相似度为
0.7107,这是
中等偏高的相似度 。为什么不是接近 0(完全不同)或
1(几乎相同)?
两个 bank
的词形相同、词性相同(名词),且句子里它们都处在相对相似的语言结构(“the
bank …”、“… river bank”),因此模型在某些维度上仍保留了共同信息(例如
“名词/地名/机构” 的通用特征),导致相似度偏高。
同时,因为左右上下文不同(一个后接 is,一个前接
river),模型在若干语义维度上作了区分,余弦不会是 1。
BERT 是
上下文依赖的嵌入 ,但并非总能把多义词完全区分开,特别是在单句中同时出现两个
sense 时,模型可能会有一定“表示混合”。
附注
BERT中输出还有一项为pooler_output:通常是把 [CLS]
的隐藏向量做一个线性 + tanh 变换得到的句子级向量,形状
[batch_size, hidden_dim]。注意:很多下游任务或者评价句子语义时,不一定推荐直接用
pooler_output,更稳妥的做法是对
last_hidden_state 做平均池化或用专门的句向量模型(如
Sentence-BERT)。
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 from transformers import BertTokenizer, BertModel, AutoTokenizer, AutoModelimport torchimport torch.nn.functional as Fsentences = [ ["A man is playing guitar." , "There is a man playing a musical instrument, which likes a guitar" ], ["A women is playing violin." , "The capital of France is Paris" ], ] bert_name = "bert-base-uncased" bert_tokenizer = BertTokenizer.from_pretrained(bert_name) bert_model = BertModel.from_pretrained(bert_name) sbert_name = "sentence-transformers/all-MiniLM-L6-v2" sbert_tokenizer = AutoTokenizer.from_pretrained(sbert_name) sbert_model = AutoModel.from_pretrained(sbert_name) def get_bert_sentence_embedding (sentence ): inputs = bert_tokenizer(sentence, return_tensors="pt" , truncation=True ) with torch.no_grad(): outputs = bert_model(**inputs) embeddings = outputs.last_hidden_state mask = inputs['attention_mask' ].unsqueeze(-1 ) return (embeddings * mask).sum (1 ) / mask.sum (1 ) def get_sbert_sentence_embedding (sentence ): inputs = sbert_tokenizer(sentence, return_tensors="pt" , truncation=True ) with torch.no_grad(): outputs = sbert_model(**inputs) embeddings = outputs.last_hidden_state mask = inputs['attention_mask' ].unsqueeze(-1 ) return (embeddings * mask).sum (1 ) / mask.sum (1 ) for ss in sentences: print (ss) embeddings_bert = [get_bert_sentence_embedding(s) for s in ss] cos_sim_bert = F.cosine_similarity(embeddings_bert[0 ], embeddings_bert[1 ]).item() print ("🔹 BERT pooler_output 相似度:" , round (cos_sim_bert, 3 )) embeddings_sbert = [get_sbert_sentence_embedding(s) for s in ss] cos_sim_sbert = F.cosine_similarity(embeddings_sbert[0 ], embeddings_sbert[1 ]).item() print ("🔹 Sentence-BERT 相似度:" , round (cos_sim_sbert, 3 ))
1 2 3 4 5 6 ['A man is playing guitar.', 'There is a man playing a musical instrument, which likes a guitar'] 🔹 BERT pooler_output 相似度: 0.787 🔹 Sentence-BERT 相似度: 0.877 ['A women is playing violin.', 'The capital of France is Paris'] 🔹 BERT pooler_output 相似度: 0.46 🔹 Sentence-BERT 相似度: 0.015